Ce qui se passe chez K-AI
Événements, partenariats, prises de parole — K-AI dans l’écosystème IA français et européen.

Gouvernance des agents IA 2026 : 53 % opèrent sans politique — la qualité du corpus, pilier manquant
Sur 740 dirigeants Sinequa (juin 2026), 53 % n'ont aucune politique de gouvernance pour leurs agents IA. L'angle mort : la qualité du corpus qu'ils interrogent.

RAGAS, DeepEval, LettuceDetect : pourquoi l'évaluation RAG est aveugle aux défaillances documentaires
RAGAS, DeepEval, LettuceDetect mesurent la fidélité au contexte récupéré — pas la fiabilité du corpus. L'angle mort de votre évaluation RAG.

Votre Confluence entraîne désormais l'IA d'Atlassian. Ce que le DSI doit décider avant le 17 août.
Atlassian active par défaut l'entraînement IA sur Confluence et Jira le 17 août. Le bon réflexe DSI : auditer l'état du corpus avant de cocher l'opt-out.

Document Knowledge Platform (DKP) : définition, différences avec GED et ECM, et guide de sélection 2026
GED, ECM, SharePoint, RAG — et DKP : ce ne sont pas des synonymes. Définition d'une Document Knowledge Platform et comment savoir si vous en avez besoin.

RAGOps : la moitié « données » que personne n'opère — SLI, SLO et control plane pour la santé de votre corpus
Le RAGOps inclut la gestion continue du corpus. Un an après le papier fondateur, personne ne l'opérationnalise. Voici les SLI du corpus en production.

IA agentique sans fondations documentaires : pourquoi 64 % des entreprises construisent sur du sable
Hyland GA son Context Engine, Semarchy chiffre le MDM gap. Personne ne nomme la couche d'amont : le corpus documentaire.

K-AI à VivaTech 2026 — rendez-vous à Paris, 17-19 juin (avec TotalEnergies)
Rendez-vous à VivaTech 2026 avec TotalEnergies — stands Hall 2 (2H08-001) et Hall 3D (3D37-010). Démos DKP en live les 17-19 juin.

AI Act 2 août 2026 : ce que le Digital Omnibus n'a pas reporté — et le plan corpus en 60 jours
Digital Omnibus a repoussé l'Annexe III à décembre 2027 — pas l'Article 50, pas l'Annexe IV des systèmes déjà en marché. Plan corpus 60 jours.
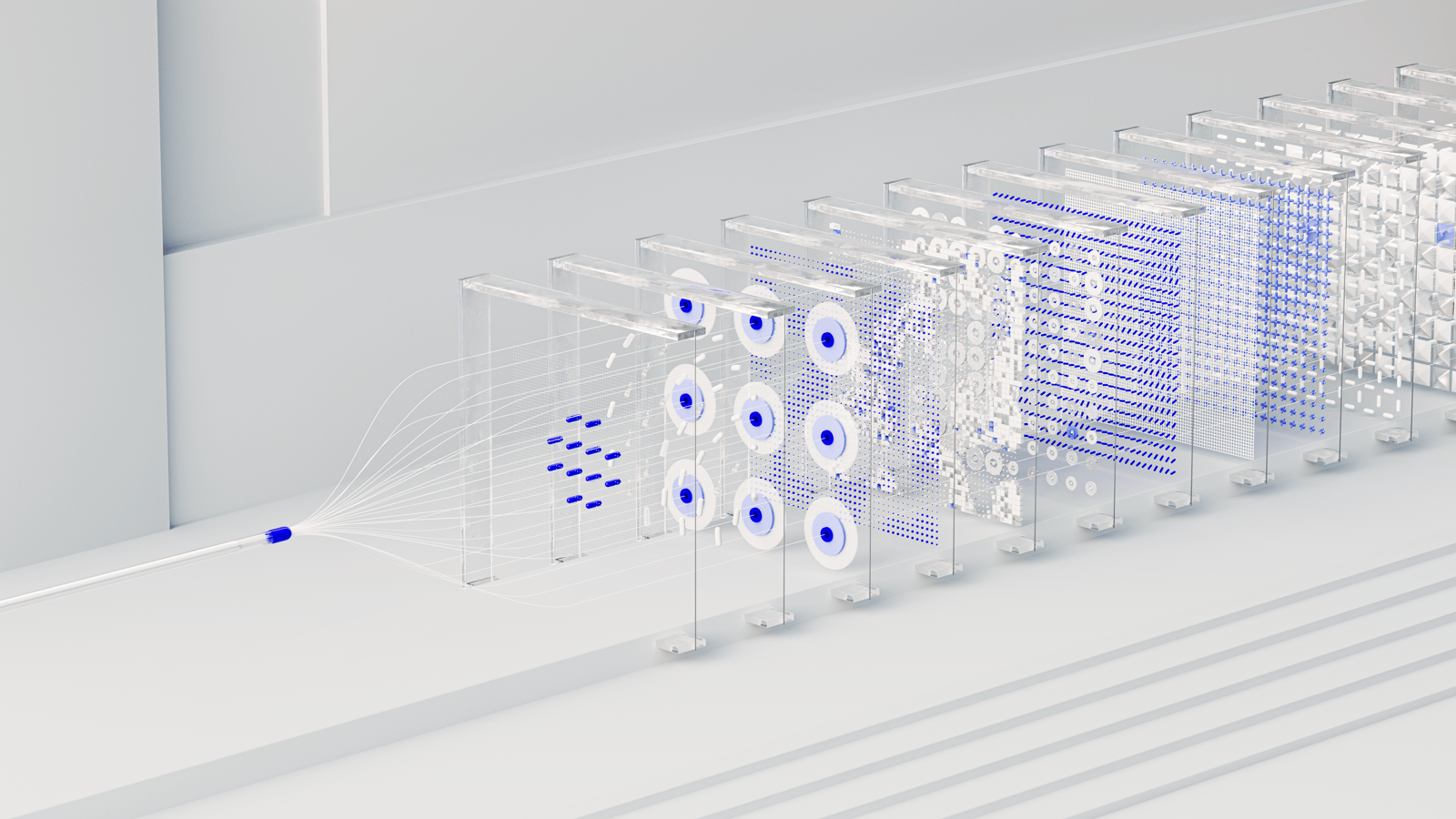
Context engineering done right : pourquoi ce paradigme post-RAG exige un corpus propre
Anthropic, Glean, LangChain, Pinecone, LlamaIndex ont posé la grammaire du context engineering. Tous travaillent en aval du corpus. Et personne ne le dit.

Le RAG ne résout pas l'hallucination, il la déplace : la contradiction inter-sources
Le RAG est le dogme 2026 du déploiement IA en entreprise. Pourtant la production échoue en série — et la cause #1 n'est ni l'embedding ni le LLM.
AI Readiness Assessment 2026 — le pillar « Corpus » que tous les frameworks oublient
Cinq frameworks AI Readiness 2026 — Cisco, Microsoft, Cloudera, Iris.ai, Atlan. Aucun n'érige le corpus en pillar autonome. Pourquoi ce vide coûte cher.

Knowledge Graph vs base vectorielle pour un RAG d'entreprise — commencez par le corpus
Microsoft, Pinecone, Neo4j, Glean, Squirro, Writer ont publié leur guide « Knowledge Graph vs vector database ». Ce que ni le graph ni le vector ne corrigent.